The inputs make up the information that goes into a pretrial RAT.
They are the variables that are weighed to calculate someone’s ultimate risk score.
Different pretrial RATs use different inputs to determine risk scores. Jurisdictions may use as few as 4 or as many as 100 variables within their tools.
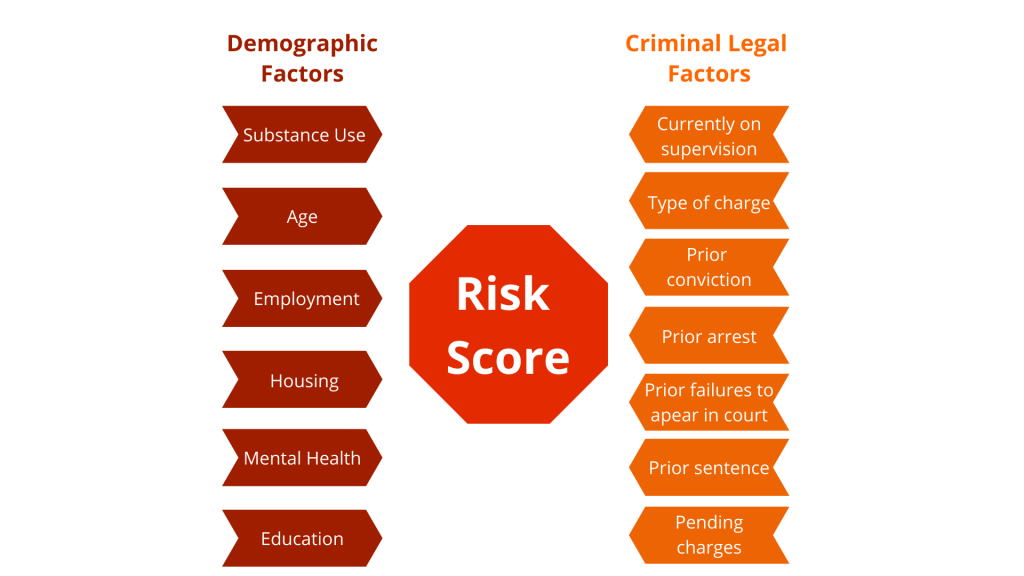
Variables include information about an individual’s criminal legal system history, such as previous arrests or convictions. Some common criminal history-related factors used for RAT prediction we found in our research include the type of charge someone is arrested for, prior convictions, prior arrests, prior failures to appear, having a pending charge at the time of arrest, being on active supervision (such as probation) at the time of arrest, and prior sentences.
Many RATs also include some demographic information that relates broadly to race and economic status. Common demographic factors we found in our research include age, a history of substance use, employment status, housing status, mental health, and education level.
Some tools are considered proprietary, and the exact variables and weights for each variable remain a mystery to the public.
The weight developers give each variable differs between tools as well.
Each tool assigns point values to each variable it uses. These point values determine how much each factor impacts the total score and ultimately an individual’s reported risk level. Weights are based on how significant RAT developers find each variable to be in predicting the chances of failure to appear and re-arrest.
In calculating FTA scores and in trying to predict new arrests, some tools give the most points to previous failures to appear, while others weigh past arrests or convictions most heavily. Demographic data points, such as age, are also counted more heavily in some tools than others.
So, although many tools use similar variables, every tool weighs factors differently. This means that each individual variable could impact an individual’s risk level very differently, depending on which tool is used to evaluate them, how that tool has been calibrated for an individual jurisdiction, and how that tool is interpreted by a specific decision-making framework.
The same person could get vastly different scores and therefore different pretrial outcomes in different places.