Often, developers of risk assessment tools (RATs) describe tools as recently or locally “validated,” hoping this indicates scientific accuracy to those who might adopt a tool. But what is validation? Validation means statistically determining how well a RAT measures what it is designed and calibrated to measure.
As researchers Sarah Desmarais and Evan Lowder explain, “For pretrial risk assessment tools to be considered “valid,” they must be able to estimate the probability of failure to appear and/or pretrial rearrest at statistically significant and politically acceptable rates.”1Sarah L Desmarais and Evan M Lowder: Pretrial Risk Assessment Tools: A Primer for Judges, Prosecutors, and Defense Attorneys, MacArthur Foundation Safety and Justice Challenge
Using past data about real people who were caught up in the criminal legal system, researchers apply the RAT to cases where they already know if someone was re-arrested or did not come to court following pretrial release. They can then compare what the RAT predicts would happen to what actually happened.2Sandra G Mayson: Dangerous Defendants, Yale Law Journal
However, validation studies do not consider people who were never released pretrial, limiting the “validity” of validation statistics.
Explore how designers attempt to determine “accuracy” of a RAT with this interactive tool from MIT Technology Review.3Karen Hao and Jonathan Stray: Can you make AI fairer than a judge? Play our courtroom algorithm game, MIT Technology Review
Validation of pretrial RATs does not have a standardized definition across different jurisdictions.4Cynthia A. Mamalian: State of the Science of Pretrial Risk Assessment, Pretrial Justice Institute Different jurisdictions have validated their tools in different ways, some internally and some with an external independent researcher.
Plus, just because a tool is validated does not mean it is perfectly accurate or transparent about how it operates, or that it is calibrated for a local community.5Brandon Buskey and Andrea Woods: Making Sense of Pretrial Risk Assessments, The Champion
The Pretrial Justice Institute’s 2019 Scan of Pretrial Practices6Pretrial Justice Institute: Scan of Pretrial Practices (2019) report found that only 45% of the jurisdictions they surveyed had validation studies.
In our research, the majority of validation studies were not conducted by an independent or third party researcher. Many jurisdictions are using tools that have not been validated with their local population or have not been validated at all.
The graph below depicts how often the jurisdiction we interviewed had been validated locally.
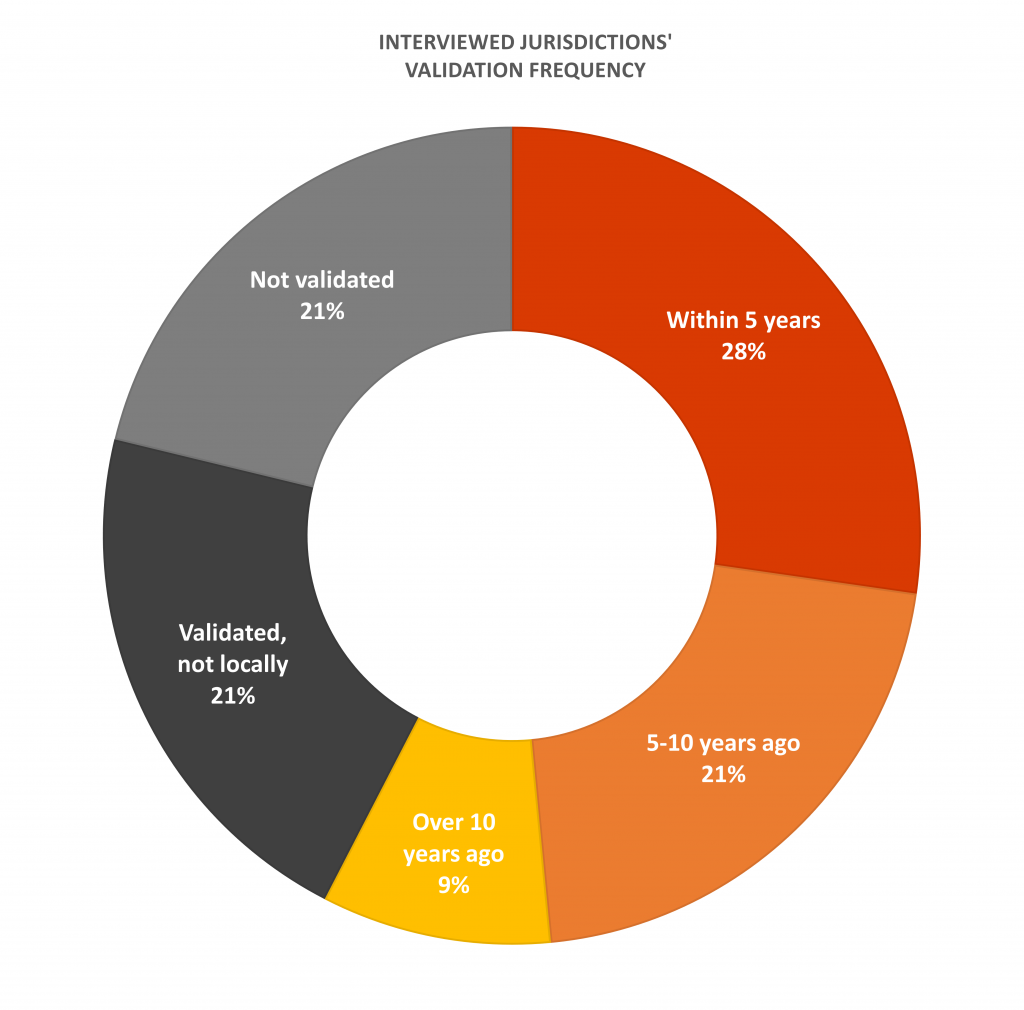
Total number of jurisdictions with validation information = 33
How does validation work?
Validation reports document the relationship between assessment results and actual outcomes for groups. Like algorithms, validation reports are done in the aggregate, not for specific individuals.
Validation studies measure predictive validity. They help determine whether pretrial RATs accurately predict whether the outcome for a person in the study set would be the same for the accused person being judged by the RAT today.
A common statistical way of measuring accuracy and predictive validity is through the “area under the curve,” or AUC. The AUC score is supposed to show how well the tool balances its correct and incorrect predictions — how often it correctly answers the question at hand (like how “risky” someone is), and how often it gets the prediction wrong.
The closer an AUC score is to 1, the more accurate a tool is said to be. An AUC score of 0.5 is no better than chance in predicting risk7Pamela M Casey, Jennifer K Elek, Roger K Warren, Fred Cheesman, Matt Kleiman, and Brian Ostrom: Offender Risk & Needs Assessment Instruments: A Primer for Courts, National Center for State Courts: a 50/50 shot.
Some RATs have AUC scores as low as 0.55, barely more accurate than random chance or a coin toss. Several common tools have scores around 0.65, which is considered “good” in criminology research8Sarah L Desmarais and Jay P Singh: Risk Assessment Instruments Validated and Implemented in Correctional Settings in the United States, Council of State Governments Justice Center but “poor” in other fields9Saeed Safari, Alireza Baratloo, Mohamed Elfil, and Ahmed Negida: Evidence Based Emergency Medicine; Part 5 Receiver Operating Curve and Area under the Curve, Emergency; a score of 0.65 means over one third of those judged by these tools are being mislabeled.
And unlike many other fields, there is a lack of independent evaluation of these validation studies, which severely limits any claims that pretrial RATs are truly predictive.10Sarah L Desmarais and Evan M Lowder: Pretrial Risk Assessment Tools: A Primer for Judges, Prosecutors, and Defense Attorneys, MacArthur Foundation Safety and Justice Challenge
Sarah Desmarais and Evan Lowder point out that “demonstrating predictive validity does not equate with research demonstrating implementation success.”11Sarah L Desmarais and Evan M Lowder: Pretrial Risk Assessment Tools: A Primer for Judges, Prosecutors, and Defense Attorneys, MacArthur Foundation Safety and Justice Challenge Even if a tool is considered highly “accurate” by these standards, it doesn’t mean that RATs are being implemented as intended or in a decarceral or racially unbiased way. The predictions they make are not always accurate, not always listened to even if accurate, and are applied inconsistently and in structurally racist ways.
